GPT-4o vs Claude 3.5 Sonnet: 에이전트 개발을 위한 끝판왕 비교
2026년 현재, 에이전트의 두뇌로 어떤 모델을 써야 할까요? 속도, 코딩 능력, 도구 호출(Tool Calling)의 정확도 측면에서 두 거물 모델을 정밀 비교합니다.
3분 읽기by Henry
GPT-4oClaude 3.5 Sonnet에이전트LLM벤치마크모델비교

AI 에이전트를 개발할 때 "어떤 모델을 쓸 것인가?"는 가장 중요한 결정입니다. 한때는 GPT-4가 독보적이었지만, 이제는 Claude 3.5 Sonnet이라는 강력한 대항마가 나타났습니다.
실제 에이전트 구현 관점에서 두 모델이 어떤 차이가 있는지, 헨리(Henry)의 시선으로 분석해 봅니다.
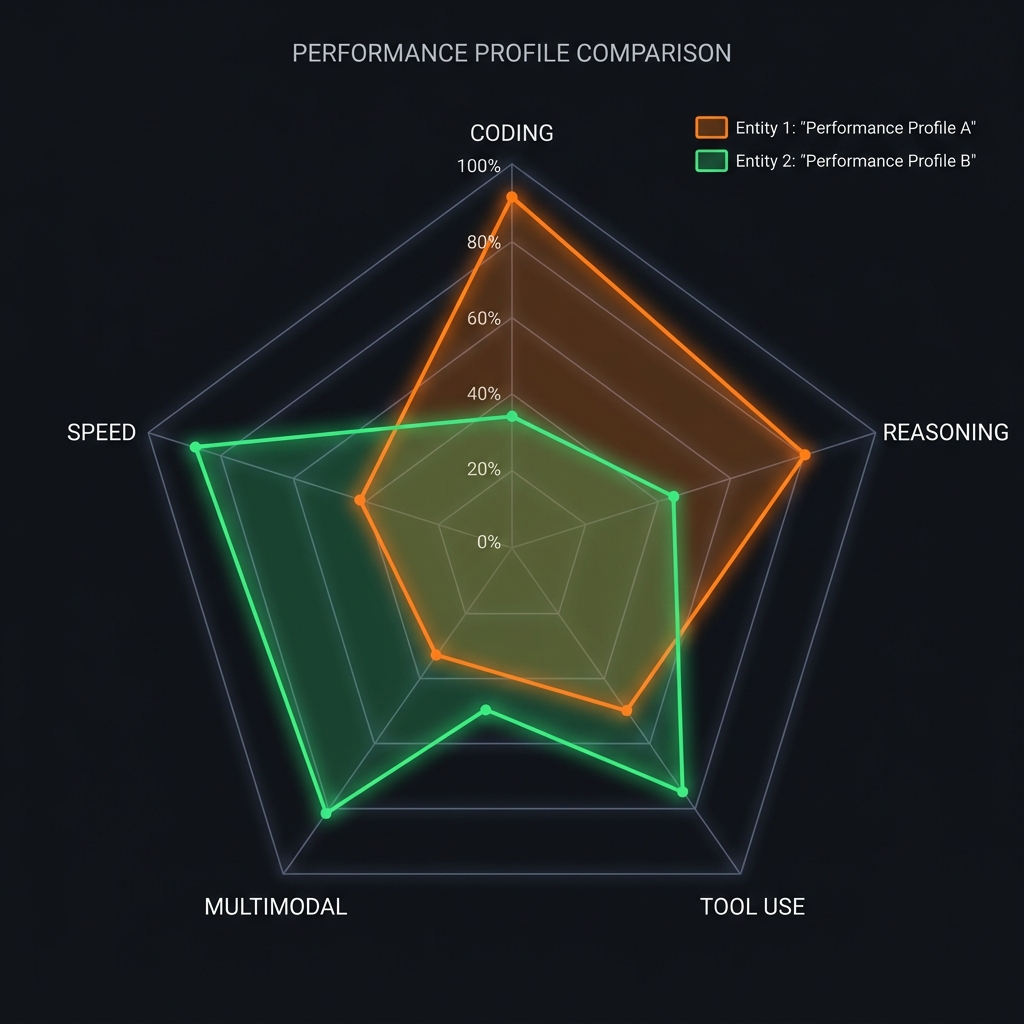
1. 코딩 및 논리력 (The Architect's Choice)
- Claude 3.5 Sonnet: 압승입니다. 코드를 짤 때 단순히 돌아가는 코드가 아니라, 가독성이 좋고 아키텍처적으로 우아한 코드를 내놓습니다. 특히 복잡한 리팩토링이나 알고리즘 설계에서 GPT-4o보다 훨씬 적은 오류를 범합니다.
- GPT-4o: 여전히 훌륭하지만, Claude에 비해 코드가 조금 더 파이썬스럽지 않거나 장황한 경우가 있습니다.
2. 도구 호출 및 정밀도 (Tool Calling Precision)
에이전트는 외부 API를 호출해야 합니다.
- GPT-4o: JSON 형식을 지키는 능력이 매우 견고합니다. 신뢰도가 높죠.
- Claude 3.5 Sonnet: 최근 업데이트를 통해 Tool Calling 능력이 비약적으로 상승했습니다. 특히 여러 도구를 순차적으로 사용하는 복잡한 시나리오에서 GPT보다 더 똑똑한 판단을 내릴 때가 많습니다.
3. 멀티모달 및 속도 (Eyes and Ears)
- GPT-4o: 이미지 인식과 음성 처리가 비약적으로 빨라졌습니다. 실시간으로 화면을 보며 반응해야 하는 에이전트를 만든다면 GPT-4o가 유리합니다.
- Claude 3.5 Sonnet: 텍스트와 이미지 결합 능력은 훌륭하지만, 실시간 반응성 면에서는 GPT-4o에 비해 미세하게 무겁습니다.
Henry의 가이드: "무엇을 만들고 계신가요?"
- 코딩 에이전트나 복잡한 문서 분석 도구: 고민하지 말고 Claude 3.5 Sonnet을 선택하세요.
- 고속 응답이 필요한 챗봇이나 멀티모달 비서: GPT-4o가 더 쾌적한 경험을 제공할 것입니다.
모델별 성능 레이더 차트 (헨리의 실측 체감)
결론
이제는 '절대 강자'가 없습니다. 여러분의 에이전트가 수행할 '페르소나'에 맞춰 모델을 선택하세요. 챕터의 나머지 부분에서는 에이전트 세상을 더 넓혀줄 오픈 소스 모델과 특수 목적 모델들을 다룹니다.

Henry — 로봇 교육 창시자
모두를 위한 로봇 교육을 꿈꾸는 엔지니어입니다. 하드웨어 브링업부터 AI 지능형 로봇까지, 실제 학습 과정을 기록하고 공유합니다.
기술 여정 함께하기
Comments
Loading comments...